
Feature your business, services, products, events & news. Submit Website.
Breaking Top Featured Content:
Understanding Subresource Integrity
Understanding Subresource Integrity
Drew McLellan
If you’ve ever used a CDN-hosted version of a JavaScript library, you may have noticed a strange looking integrity attribute on the script tag. This attribute contains seemingly endless alphanumeric junk that you may be tempted to strip out in the quest for cleaner code.
All that junk is actually a really useful security feature called Subresource Integrity (SRI) that can help to defend your site against certain types of hacks and compromises. In this article, we’ll take a look at what SRI is, how it can help protect you, and how you can start using it in your own projects, not just for files hosted on CDNs.
A Bit Of History
Way back in the days when JavaScript was very much the poorer cousin to HTML and CSS, we didn’t need to think too much about how our scripts could be used as an attack vector for our websites. Most sites were all hosted on a single physical server somewhere on our own hosting infrastructure, and it was the server we thought about defending when it came to security best practices.
As browsers became more capable and net connections got fatter, we started to use more and more JavaScript, and eventually, reusable JavaScript libraries began to spring up. In those early days, libraries like script.aculo.us, Prototype and eventually jQuery began to gain adoption amongst developers looking to add more interactivity into their pages.
With these added libraries and subsequent plugins came added page weight, and before long we were starting to think seriously about front-end performance. Resources like Content Delivery Networks (CDNs) that had previously been the reserve of giant corporations were becoming commonplace for everyday folk building snappy websites.
Along the way, some bright spark noticed that sites were all requesting their own copies of common libraries — things like the latest jQuery — and if there was a common CDN version of those libraries that could be used by every site, then the user wouldn’t need to keep downloading the same file. They’d take the hit for the first site to use the file, but then it would sit in their local browser cache and downloads could be skipped for each subsequent site. Genius!
This is why you’ll see CDN links for your favorite libraries using URLs like jsdelivr.com — they’re making use of a common CDN to host the files so that their users see the performance benefits.
What Could Go Wrong?
This remains a good, practical way to work, but it does introduce a potential vector for attack. Let’s imagine that it’s 2012 and everyone is using the brand new jQuery 1.8. Back with the traditional way of doing things, everyone would have their own jQuery 1.8 file hosted as part of their own website on their own server.
If you were some kind of evil actor — like some sort of jQuery-based Hamburglar — and had figured out a sneaky way to hack the library for your own evil gains, you’d have to target every website individually and compromise their servers to have any impact. That’s a lot of effort.
But that’s not how things are now, as everyone is using jQuery loaded from a common CDN. And when I say everyone, I don’t mean hundreds of web pages. I mean millions of web pages. Suddenly that one file has become a very attractive target for our shady hacker. If they can compromise that one file, they can very quickly have code running in millions of web pages across the globe.
It doesn’t matter what that code is. It could be a prank to deface pages, it could be code to steal your passwords, it could be code to mine cryptocurrency, or it could be sneaky trackers to follow you around the web and make a marketing profile. The important thing is that the innocent file that the developer added to a page has been changed and you now have some evil JavaScript running as part of your site. That’s a big problem.
Enter Subresource Integrity
Rather than rolling back the clocks and abandoning a useful way to use code, SRI is a solution that adds a simple level of security on top. What SRI and the integrity attribute does is make sure that the file you linked into a page never changes. And if it does change, then the browser will reject it.
Checking that code hasn’t changed is a very old problem in computer science and thankfully it has some very well established solutions. SRI does a good job of adopting the simplest — file hashing.
File hashing is the process of taking a file and running it through an algorithm that reduces it to a short string representation, known as a hash or checksum. Without getting into the weeds, the process is either repeatable or reversible, so much that if you were to give someone else a file along with the hash they’d be able to run the same algorithm to check that the two match. If the file changes or the hash changes, then there’s no longer a match and you know something is wrong and should distrust the file.
When using SRI, your webpage holds the hash and the server (CDN or anywhere) holds the file. The browser downloads the file, then quickly computes to make sure that it is a match with the hash in the integrity attribute. If it matches the file is used, and if not it is blocked.
Trying It Out
If I go to getbootstrap.com today to get a CDN link to a version of Bootstrap, I’m given a tag that looks like this:
You can see that the src attribute is as we’re used to, and the integrity attribute holds what we now know to be a hash.
The hash is actually in two parts. The first is a prefix to declare which hashing algorithm to use. In this case, it’s sha384. This is followed by a dash and then the hash itself, encoded with base64.
You may be familiar with base64 as a way of encoding inline files like images into pages. It’s not a cryptographic process — it’s just a fast and convenient way to encode potentially messy data in a way that translates neatly to ASCII. This is why it’s used a lot on the web.
On seeing this, the browser will download bootstrap.min.js. Before executing it, it will base64 decode the hash and then use the sha384 hashing algorithm to confirm that the hash matches the file it’s just downloaded. If it matches, the file is executed.
I can test this out by putting that tag in a page, and then flipping to the Network tab in my browser tools to see that the file has been loaded.
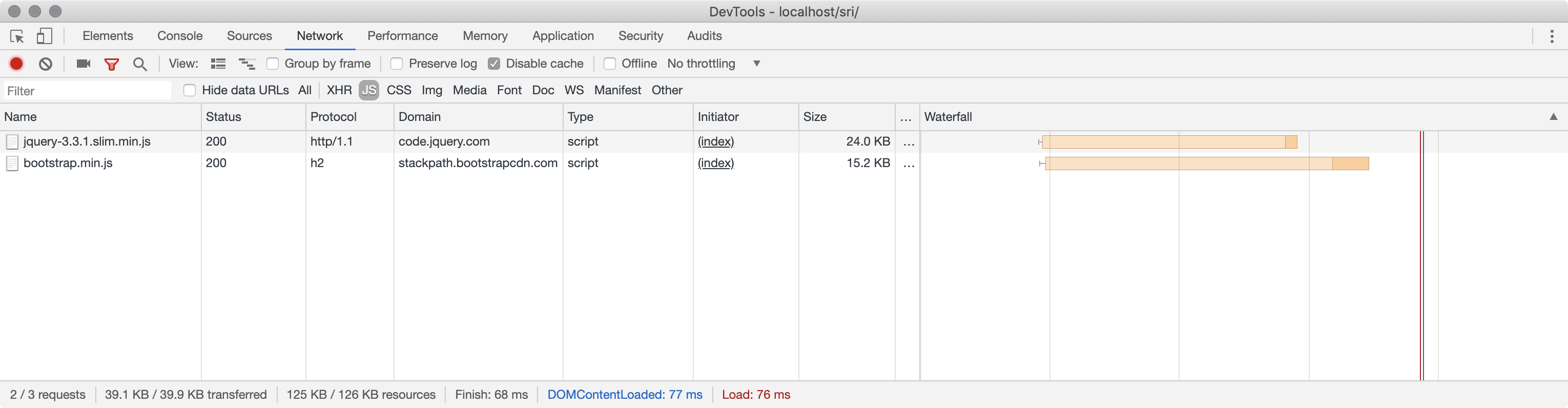
I can see that bootstrap.min.js (and also the jQuery file it needs) have loaded successfully.
Let’s see what would happen if I update the hash to be something I know to be incorrect.

As you can see, the hash that’s specified in my page no longer matches the file, so the file gets blocked.
Using SRI In Your Own Projects
Having this capability for libraries on a CDN is great, and if you see the option to use an embedded file with an integrity attribute then you should definitely favor that option. But it’s not limited to big projects on CDNs, you can use this yourself for your own sites.
It’s not at all far fetched to imagine a scenario where a hacker manages to get access to just a few files on your site. I think most of us have see a client, colleague or friend who has at some point had a WordPress site compromised with a load of nasty junk that they didn’t even realise was there.
SRI can protect you from this too. If you generate integrity hashes for your own files, then you can have your site reject any changes just as it would for a remotely hosted file.
Generating Hashes
You can, as you’d expect, run some commands at your computer’s terminal to generate a hash for a file. This example of how to do so comes from the MDN Subresource Integrity page:
cat FILENAME.js | openssl dgst -sha384 -binary | openssl base64 -A
That’s getting the content of FILENAME.js and passing it as input to openssl to create a digest using sha384, which is then passed as input into another openssl command to base64 encode the result. Not only is that complicated and obscure, but it’s also not the sort of thing you want to be doing by hand every time your JavaScript file changes.
More usefully, you’ll want to integrate this somehow into your site’s build process, and as you’d imagine, there are plenty of ready-made options there. The exact implementation is going to vary wildly based on your project, but here are some building blocks.
If you use Gulp to build your sites, there’s gulp-sri which will output a JSON file with a list of your files and their hashes. You can then make use of this in your site. For example, for a dynamically rendered site, you might create a template plugin to read that file and add the hashes to your templates where needed.
If you’re still with Gulp but have a static site (or a statically generated site) you might use gulp-sri-hash which will actually run through your HTML pages and modify the pages to add hashes where needed, which is very handy.
If you’re using Webpack, there’s webpage-subresource-integrity which in true Webpack style is more complex than any human might expect it to be, but does appear to work.
For those using the Handlebars templating engine, there appear to be options available to you, and if your build process is just basic JavaScript, there are simple solutions there too.
If you’re using a CMS like WordPress, I found a plugin that appears to make it easy, although I’ve not tried it myself. Googling for your own platform of choice with SRI or Sub Resource Integrity will likely point you in the right direction.
You essentially want to hook your hashing in after your JavaScript files have been minified and then make that hash available in some way to whatever part of your system outputs the